magi.com 知识片段详情页的深度解读
本文是对 magi.com 使用帮助 中知识片段的详情页的进一步说明,希望能对您有帮助。
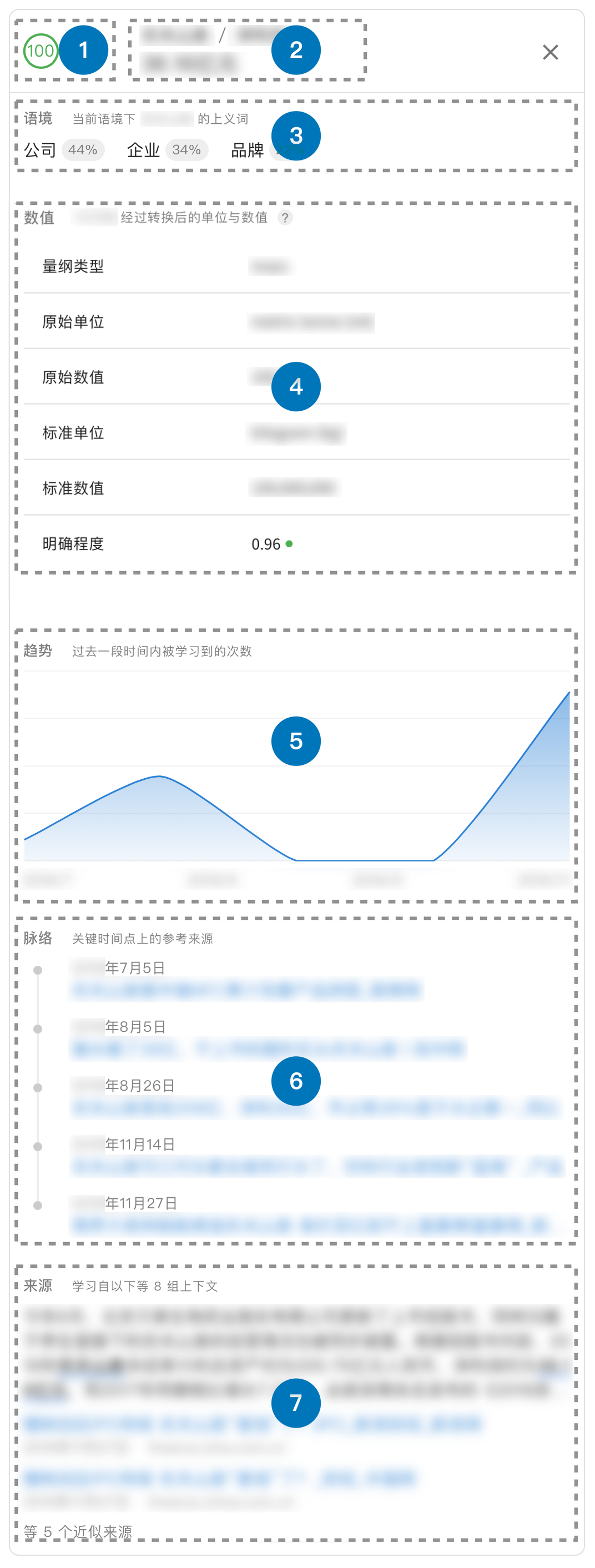
可靠性评分(1)
这里 Magi 的打分,是其对自身学习到该知识片段这一过程的可靠性估计,而不是任何形式的概率估计、事实判断、立场评价、主观打分等。
打个比方的话,该分数是 Magi 在给自己判卷子的时候打的分,获取相应知识片段这个任务相当于一道复杂大题。Magi 会像评价解题过程的各个步骤一样,综合考量其学习知识的来源网站、文档本身、行文、格式、逻辑、有没有其他来源可供交叉验证等各个维度的特征,为其本次学习打分。自然,来自权威网站、文档内容明晰、行文通顺、格式端正、逻辑明确、有更多可供交叉验证的来源的内容会让 Magi 倾向于认为此次学习正确的可能性更高,从而给予更高的评分。
知识片段(2)
体现被激活的具体知识片段。
语境(3)
此处的语境是为了方便区分同名实体而展示的,表示该知识片段是在实体作为某种特定解读(语境)下学习到的。此处列举的上义词即为 Magi 判断该知识片段中实体的具体分类。比如有的实体可能既是公司名又是食物,那不同语境的区分就是很有必要的。
数值(4)
传统的关系提取模型通常提取的是实体与实体之间的某几种关系,而对于实体和数值这样的关系类型支持有限。Magi 不仅能够不限制关系类型提取实体之间的关系,同时也支持实体与数值等非实体类型的信息之间的关系提取。
为了方便需要依赖数值进行的后续处理,Magi 支持将多种表述方式的描述数值的文本提取为纯数值类型,同时智能识别该数值对应的量纲类型,并根据该量纲类型下的国际单位进行单位转换。经过了单位转换之后,不论是数值之间的比较还是后续计算都将更容易进行。
数值提取下的明确程度,指的是该语境下文本片段属于特定量纲类型的明确度,明确度较低意味着量纲类型的识别可能有差错,例如“度”是被识别为角度还是温度这样的场景。这里的明确程度不应被理解为该知识或者数值提取的准确度。
趋势(5)
知识往往也会随着时间发生变化,像是体育明星效力的球队、公司的经营状况这样的信息甚至可能年年发生变动。为了更好地展示信息随时间发生的变化,Magi 会根据学到信息的频次和与该信息相关的具体时间点,来绘制趋势图。
趋势图上的横轴是时间轴,指的是相应信息被学习到的时间。由于网络上刊载的内容的真实时间出处往往难以考证,Magi 会综合考虑网站本身、来源的生成时间、来源内记载的时间、相关内容能否被交叉验证等多重因素,估计出一个相关信息对应的时点。
趋势图上的纵轴体现的是单位时间内学习到特定信息的次数。请注意,纵轴代表的并非信息被学习到的次数的直接体现。由于数量级并不直接可比,趋势图上的各个点的纵轴对应数值是经过一定换算得到的。趋势图仅供对比在该条信息内,不同时间点下的频次的相对多少,不应被用来进行严肃计算或者精确比较。
脉络(6)
一些时间点会被认为对特定信息有较显著的影响,可能的原因包括该时间点信息有重要变化、相关文章数量有显著变化等。这些时间点被视作关键时间点。
Magi 会根据一定标准,选取在各个关键时间点上较具有表性的来源,按照时间顺序整理为该信息的脉络,展示于趋势图的下方。用户可以通过脉络快速访问相关信息在对应时点最具代表性的来源。
来源(7)
Magi 基于开放领域的纯文本构建相对可靠的知识图谱,在此过程中的许多因素都可能影响最终质量:如提取模型自身的准确率、非客观陈述语境、低质量或误导性内容、洗稿与恶性 SEO 等等 —— 这与学术出版领域面临的挑战非常相似:如研究者自身的水平、预设立场或结论的研究、低质量灌水、非原创内容等。在学术界,一篇论文的被引用次数是衡量其质量的重要标准之一。一篇文论被引用次数越多,则代表有更多的人进行了验证,因此可靠性会较高。在搜索领域,这一思想被应用在了基于链接分析的排序技术中,并取得了卓越的成效。
Magi 将交叉参考引入了信息抽取与知识图谱构建系统:如果某一信息被更多的来源以多种不同的形式表达过,则代表该信息经过了更多人的验证,因此更加可靠。需要指出的是,该过程是自下而上的,即发生于每次信息抽取时,而非简单地使用提取出的信息进行文本召回获得数量。这一设计的好处是,Magi 不仅有机会确认相关信息在上下文中是语义成立的(而非单纯关键字匹配),同时还可以对来源进行需要大量计算的基于稠密向量的聚类分析。聚类分析将过于相似的来源归并为同一上下文组,从而降低转载和洗稿内容的权重。各上下文组的特征向量之间的相似度量化了提取模型输入的多样性,使得其可作为参数参与最终可信度的计算。